
Deploying new code always carries the risk of unexpected failures, yet downtime isn’t acceptable for most businesses. A canary deployment tackles this problem by routing only a controlled slice of live traffic to the new version while the stable release continues to serve everyone else. This direct comparison surfaces regressions early, lets teams reverse instantly with one routing change, and produces real-world performance data that test environments cannot match. With the fundamentals clear, the following sections break down the process, show measurable gains, flag common pitfalls, and outline the tools that make canary rollouts routine.
How Do Canary Deployments Work?
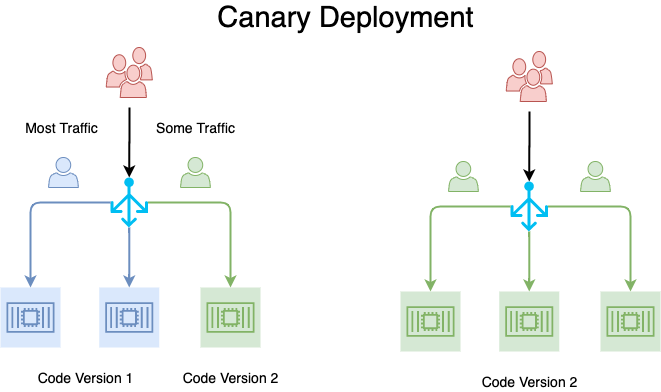
The pipeline first tags the new container image and stores it in the registry. Next, deployment code spins up a small replica set running version B beside the larger set running version A. A router or service mesh then directs a small fraction of live requests—often five percent—to version B while the rest continue to reach version A. Monitoring stacks capture latency, error counts, and business throughput on both versions. If every metric stays within tolerance, the router raises version B’s weight during the next window and repeats the measurement. If any metric exceeds its guardrail, the router sends all traffic back to version A, which keeps user impact low.
| Stage | Traffic Split | Primary Gate | Next Action |
| Deploy B | 0 % | Pods healthy | Start first window |
| Window 1 | 5 % B, 95 % A | Latency ≤ baseline +10 % | Grow slice or roll back |
| Window 2 | 25 % B, 75 % A | Error rate ≤ baseline +0.2 % | Grow slice or roll back |
| Window 3 | 50 % B, 50 % A | Revenue steady | Grow slice or roll back |
| Cut-over | 100 % B | Stable two windows | Remove version A |
The percentages and window length vary by traffic volume, but every step follows the same measure-then-decide loop.
Benefits of Canary Deployments
A canary strategy adds observable safety to every push. Because the trial slice runs in production, the technique supplies real performance data that staging clusters cannot fake. It also keeps rollback cheap because a single weight change in the router reverses the release. Continuous delivery teams adopt canaries to ship smaller commits more often, which shrinks change size and lowers mean time to recovery.
| Benefit | Why It Matters | How to Measure Success |
| Lower blast radius | Defects reach only the trial slice | Support tickets never spike during rollout |
| Fast rollback | Router weight reset finishes in seconds | Change log shows rollback took < 1 minute |
| Real capacity insight | New build meets genuine load early | Autoscaler data shows stable resource usage |
| Reliable rapid delivery | Small changes plus strict gates allow daily pushes | Release calendar shifts from weekly to daily |
| Built-in A/B testing | Same router logic splits users by cookie or region | Product metrics validate feature impact |
These gains appear only when teams pair the technique with solid monitoring and clear guardrails.
Risks and Challenges
The control plane that guides traffic can fail just like application code, and any schema change that version B writes must remain readable by version A in case of rollback. Low-volume services also struggle because small slices lack statistical power. Therefore, each risk needs a matching safeguard before the first production run.
| Risk or Challenge | Operational Impact | Mitigation Strategy |
| Router mis-config | All users hit the new build at once | Store weights in version-controlled IaC and peer review every change |
| Session split | User hops between versions and loses state | Use sticky cookies or centralized session storage |
| Incompatible data writes | Rollback corrupts live data | Apply expand-migrate-contract migrations so both versions read all rows |
| Noisy metrics on low-traffic services | False confidence or false alarms | Run longer windows or choose blue-green instead |
| Alert fatigue | Operators tune out real warnings | Set thresholds from historical data and suppress flaky signals |
| Added complexity | Engineers face steeper learning curve | Pilot on one service, write a runbook, then scale out |
Understanding these pitfalls early lets a platform team design processes that keep them under control.
Real-World Use Cases
Payment processors run a canary whenever they adjust fraud-scoring logic because a faulty rule that declines valid cards hurts revenue instantly. The first five percent of transactions surfaces corner cases such as rare issuer ranges, giving engineers time to correct thresholds before full deployment.
Streaming platforms apply canaries when they switch codecs. By steering a narrow band of user sessions to the new transcoder, they watch buffer underrun rates, bandwidth savings, and playback failures under real network paths. Once metrics match or beat the baseline, they widen the slice until every viewer sees the improved stream.
High-frequency trading desks push rule tweaks behind a canary slice pointed at a single data center close to the exchange. Because even one millisecond of latency affects bid placement, operators set alerts that trigger if median latency deviates above a tight boundary.
Public cloud providers release control-plane updates through region-based canaries. North America receives the build first, Europe several hours later, and Asia last. This wave pattern gives a follow-the-sun support crew time to spot regression indicators before every tenant feels them.
Best Practices for Successful Canary Deployments
A sound rollout plan starts with numeric success metrics like latency, error budget, and revenue per minute that map directly to user value. The pipeline should query those metrics after each window and halt traffic growth automatically when a figure crosses its guardrail. Manual dashboards alone invite human delay.
Database migrations should follow an expand-migrate-contract pattern. First, add new columns or tables, then teach both versions to read and write them, migrate existing data asynchronously, and finally remove obsolete paths after the switch to version B completes. This pattern guarantees that a rollback never reads invalid rows.
Traffic progression works best on a logarithmic curve: one percent to validate basic correctness, ten percent to validate edge cases, and fifty percent to stress capacity. Going from a small slice straight to one hundred percent skips the stress test and risks a sudden overload.
Runbooks must document the exact rollback command, the paging channel, and the single source of truth for metric dashboards. Teams should rehearse the rollback on staging environments each sprint so muscle memory forms long before production nerves strike.
Finally, store router weights, metric thresholds, and gate logic in the same repository as application code. A single commit history supports audit requirements and simplifies post-incident analysis.
Tools and Platforms That Support Canary Deployments
Traffic control sits at the heart of any canary deployment, so platform choice depends on how a team wants to manage routing. Kubernetes users often start with Argo Rollouts or Flagger because both tools extend the native Deployment object and work with common service meshes. Teams that prefer managed solutions lean on cloud provider services, which hide much of the routing logic behind console toggles and APIs.
| Tool | Target Environment | Routing Mechanism | Rollback Trigger | Notable Feature |
| Argo Rollouts | Kubernetes | Mesh or ingress weight | kubectl argo rollouts undo | Built-in metric analysis and pause |
| Flagger | Kubernetes | Istio, Linkerd, App Mesh weight | Automatic when analysis fails | Integrates with Prometheus, Datadog |
| AWS CodeDeploy | EC2, ECS, Lambda | Weighted ALB or Lambda alias | One-click in console or API | Handles serverless and container targets |
| Google Cloud Deploy | GKE, Cloud Run | Backend service split | Pipeline rollback stage | Multi-region progressive targets |
| Azure DevOps | AKS, App Service | Traffic Manager portion | Release gate reset | Built-in approval workflow |
| NGINX Ingress Annotations | Any Kubernetes | canary-weight annotation | Edit weight back to zero | Lightweight entry path |
Engineers exploring canary deployment kubernetes patterns often combine these tools with Prometheus alert routes and Grafana dashboards to create a complete feedback loop.
Canary vs. Blue-Green Deployments
Blue-green strategies run two full environments in parallel and move every user at once after offline tests finish. Canary strategies keep one environment and slide traffic in measured steps. Choosing between them depends on release size, cost tolerance, and feedback needs.
| Aspect | Canary Deployment | Blue-Green Deployment |
| Traffic shift style | Incremental | Single cut-over |
| Environment cost | Lower | Higher |
| Feedback timing | Early and ongoing | Late and binary |
| Rollback method | Reset router weight | DNS or load balancer flip |
| Ideal for | Frequent small commits | Infrequent large upgrades |
Some organisations combine both approaches. They stage a fresh green stack, then run a canary slice inside that stack. This hybrid keeps environment isolation while still catching real-world faults early.
Conclusion
A properly implemented canary deployment provides a controlled on-ramp for new code, combining early real-world feedback with near-instant rollback. The tables above outline measurable gains and specific hazards, while the best-practice checklist shows how to keep the hazards small. Whether you need to convince management, prepare for an interview, or design tomorrow’s release pipeline, the points covered here let you argue the case, size the effort, and choose tooling without hunting for extra sources. If someone again asks what is canary deployment, you now have a precise, practical answer backed by clear steps and metrics.



