In the ever-expanding digital landscape, businesses rely heavily on data-driven insights to make informed decisions. Central to this process is the data warehouse, a repository that enables organizations to store, manage, and analyze large volumes of data. However, creating an efficient data warehouse involves more than just storing data; it requires careful consideration of schemas and optimization techniques. In this blog, we will explore the data warehouse design and optimization, while also looking into detailed insights for designing optimal schemas and enhancing query performance.
Data Warehouse Design
Star Schema: The Cornerstone of Efficient Data Warehouses
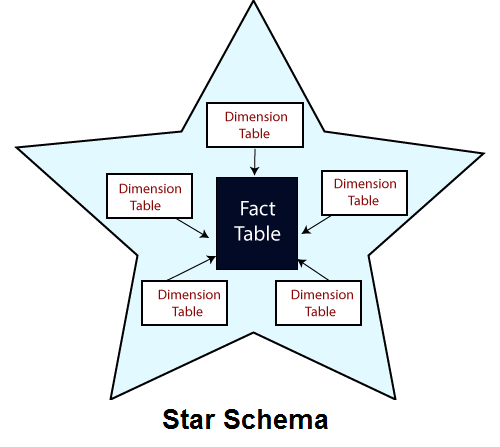
The star schema is a fundamental design technique for efficient data warehousing. At its core is a central fact table, representing the primary data entities. Surrounding this fact table are dimension tables, each providing a specific context to the data stored in the fact table. These dimension tables are connected to the fact table through primary and foreign key relationships, creating a structure that simplifies queries and ensures optimal performance.
In practical terms, consider a scenario where a business tracks sales data. The fact table might contain sales transactions, including product IDs, customer IDs, sale amounts, and dates. Linked to this fact table are dimension tables providing additional information about products, customers, and countries.
sql
— Creating Fact Table
CREATE TABLE FactSales (
SalesID INT PRIMARY KEY,
ProductID INT,
CustomerID INT,
SaleAmount DECIMAL,
SaleDate DATE,
FOREIGN KEY (ProductID) REFERENCES DimProduct(ProductID),
FOREIGN KEY (CustomerID) REFERENCES DimCustomer(CustomerID)
);
— Creating Dimension Tables
CREATE TABLE DimProduct (
ProductID INT PRIMARY KEY,
ProductName VARCHAR(255),
CategoryID INT,
FOREIGN KEY (CategoryID) REFERENCES DimProductCategory(CategoryID)
);
CREATE TABLE DimCustomer (
CustomerID INT PRIMARY KEY,
CustomerName VARCHAR(255),
CountryID INT,
FOREIGN KEY (CountryID) REFERENCES DimCountry(CountryID)
);
CREATE TABLE DimProductCategory (
CategoryID INT PRIMARY KEY,
CategoryName VARCHAR(255)
);
CREATE TABLE DimCountry (
CountryID INT PRIMARY KEY,
CountryName VARCHAR(255)
);
Snowflake Schema: Normalization for Efficiency
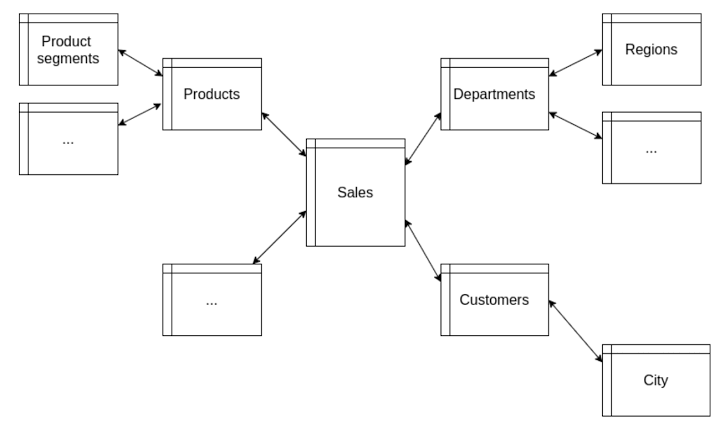
The snowflake schema extends the star schema by normalizing dimension tables. Normalization reduces redundancy, enhances data integrity, and ensures efficient use of storage space. In a snowflake schema, dimension tables are organized into multiple related tables, simplifying maintenance and improving overall data quality.
Continuing with our sales data example, the snowflake schema might involve splitting the DimProduct table further into DimProductDetails and DimProductCategory.
sql
— Creating Fact Table (Same as Star Schema)
CREATE TABLE FactSales (
SalesID INT PRIMARY KEY,
ProductID INT,
CustomerID INT,
SaleAmount DECIMAL,
SaleDate DATE,
FOREIGN KEY (ProductID) REFERENCES DimProduct(ProductID),
FOREIGN KEY (CustomerID) REFERENCES DimCustomer(CustomerID)
);
— Creating Normalized Dimension Tables
CREATE TABLE DimProductDetails (
ProductID INT PRIMARY KEY,
ProductName VARCHAR(255),
ManufacturerID INT,
FOREIGN KEY (ManufacturerID) REFERENCES DimManufacturer(ManufacturerID)
);
CREATE TABLE DimManufacturer (
ManufacturerID INT PRIMARY KEY,
ManufacturerName VARCHAR(255)
);
CREATE TABLE DimCustomer (
CustomerID INT PRIMARY KEY,
CustomerName VARCHAR(255),
CountryID INT,
FOREIGN KEY (CountryID) REFERENCES DimCountry(CountryID)
);
CREATE TABLE DimCountry (
CountryID INT PRIMARY KEY,
CountryName VARCHAR(255)
);
Optimizing Query Performance
Indexing for Speed: Boosting Query Performance

Indexing is a vital technique for improving query performance. Indexes provide a fast access path to specific rows, significantly reducing the time required for data retrieval operations. By creating indexes on frequently queried columns, you can dramatically enhance the speed of your queries.
sql
— Creating Indexes for Fact Table
CREATE INDEX idx_ProductID ON FactSales(ProductID);
CREATE INDEX idx_CustomerID ON FactSales(CustomerID);
— Creating Indexes for Dimension Tables
CREATE INDEX idx_ManufacturerID ON DimProductDetails(ManufacturerID);
CREATE INDEX idx_CountryID ON DimCustomer(CountryID);
Partitioning: Managing Large Datasets Efficiently
For large datasets, partitioning tables is an effective strategy. Partitioning involves splitting a large table into smaller, more manageable pieces, improving query performance and maintenance tasks. For example, you can partition the FactSales table based on the sale date, creating partitions for specific date ranges.
sql
— Partitioning Fact Table by Date Range
CREATE TABLE FactSales (
SalesID INT PRIMARY KEY,
ProductID INT,
CustomerID INT,
SaleAmount DECIMAL,
SaleDate DATE,
FOREIGN KEY (ProductID) REFERENCES DimProduct(ProductID),
FOREIGN KEY (CustomerID) REFERENCES DimCustomer(CustomerID)
)
PARTITION BY RANGE (YEAR(SaleDate)) (
PARTITION p0 VALUES LESS THAN (1990),
PARTITION p1 VALUES LESS THAN (2000),
PARTITION p2 VALUES LESS THAN (2010),
PARTITION p3 VALUES LESS THAN (2020),
PARTITION p4 VALUES LESS THAN (MAXVALUE)
);
Materialized Views: Precomputing Aggregations
Materialized views are precomputed summaries of data, stored as tables. They serve as a powerful optimization technique, especially for complex queries involving aggregations. By precomputing aggregations and storing the results, materialized views dramatically reduce the computational load when querying aggregated data.
sql
— Creating Materialized View for Monthly Sales
CREATE MATERIALIZED VIEW MonthlySales AS
SELECT
EXTRACT(YEAR FROM SaleDate) AS SaleYear,
EXTRACT(MONTH FROM SaleDate) AS SaleMonth,
SUM(SaleAmount) AS TotalSales
FROM
FactSales
GROUP BY
EXTRACT(YEAR FROM SaleDate), EXTRACT(MONTH FROM SaleDate);
Query Optimization: Writing Efficient Queries
Writing efficient queries is an art. Always retrieve only the necessary columns and use efficient filtering conditions to minimize the amount of data processed. Additionally, consider the use of aggregate functions judiciously, especially when dealing with large datasets.
sql
— Example of an Optimized Query
SELECT
p.ProductName,
c.CustomerName,
SUM(s.SaleAmount) AS TotalSales
FROM
FactSales s
JOIN
DimProductDetails p ON s.ProductID = p.ProductID
JOIN
DimCustomer c ON s.CustomerID = c.CustomerID
WHERE
EXTRACT(YEAR FROM s.SaleDate) = 2022
GROUP BY
p.ProductName, c.CustomerName;
Conclusion
Designing an efficient data warehouse and optimizing query performance are critical aspects of managing vast amounts of data effectively. The star and snowflake schemas serve as robust foundations, providing structures that simplify queries and ensure data integrity. By leveraging techniques like indexing, partitioning, and materialized views, you can significantly enhance query response times and streamline data retrieval operations.
Understanding your data and its usage patterns is key to making informed decisions during the design and optimization processes. Regularly monitor query performance, considering indexes, partitioning strategies, and aggregated views to continuously refine your data warehouse setup. With a well-designed data warehouse and optimized queries, you empower your organization to extract valuable insights efficiently, enabling data-driven decisions that propel your business forward.
In the ever-changing landscape of data management, mastering these techniques ensures that your data warehouse not only stores data but also serves as a powerful engine for insights, supporting your organization’s growth and strategic objectives.